Как думаешь, чем занимается дирижер? Стоит перед оркестром и отчаянно пытается вызвать своего патронуса? На самом деле, у него очень важная задача. Каждый музыкант сосредоточен на своей партии и не может охватить всю картину целиком. Тут нужен тот, кто будет слушать весь оркестр, смотреть партитуру, контролировать и управлять музыкантами, следить за тем, чтобы все играли слаженно и вступали вовремя. Короче, эффективный менеджер и крепкий хозяйственник. Запущенное приложение всегда в динамике, ровно как и музыкальная композиция. Например, в моменты кульминации, когда нужно выдать полную феерию, дирижеру нужно подключить всех, показав, что сейчас нужно играть форте (forte), ускоряя темп.
Так и в приложении, это могут быть пиковые часы нагрузки, когда нужно подкинуть побольше мощностей, чтобы выдержать ее и не повалиться (Auto-scale). Или, если незадачливый виолончелист с соло умудрился сломать свой смычок, то нужно чтобы кто-то быстро подхватил его партию. А в приложении, упавший сервис нужно как можно быстрее заменить на новый, чтобы никто даже не заметил (Auto-heal).
Ладно, долой метафоры, вот конкретика: наши сервисы зачастую запущены в контейнерах. Если кратко, то контейнер это легковесный, изолированный и переносимый пакет ПО (программного обеспечения), содержащий все необходимые компоненты для запуска приложения в любой среде. Так вот, этих контейнеров может быть дофига, и ими нужно как то управлять, балансировать нагрузку если сеть штормит, обновлять, мониторить, делать с ними домашку и укладывать спать. Кстати, про шторм, знаешь кто любит крепко подержаться за штурвал, когда корабль попадает в бурю? Рулевой или штурман! А на древнегреческий язык рулевой, он же штурман, он же кормчий переводится как «Kubernetes» (кубернетес, др.-греч. κυβερνήτης).
Итак, кубернетес, он же кубер, кубик, штурвал или кейвосемьс (k8s), это опенсорсный инструмент оркестрации контейнеров, который позволяет автоматизировать управление, мониторинг, развертывание и масштабирование приложений в контейнерах. Проще говоря, кубер помогает сделать так, чтобы приложение всегда было доступно, быстро работало во время сильных нагрузок, ну а в случае чего - быстро восстанавливалось из бекапов без потери данных. Отметим, что это не единственное решение на рынке (Docker Swarm, HashiCorp Nomad, AWS Fargate, RedHat OpenShift), но определенно самое популярное. Ну и работать кубер может не только с докером, но и другими типами контейнеров (containerd, Mirantis Container Runtime, CRI-O).
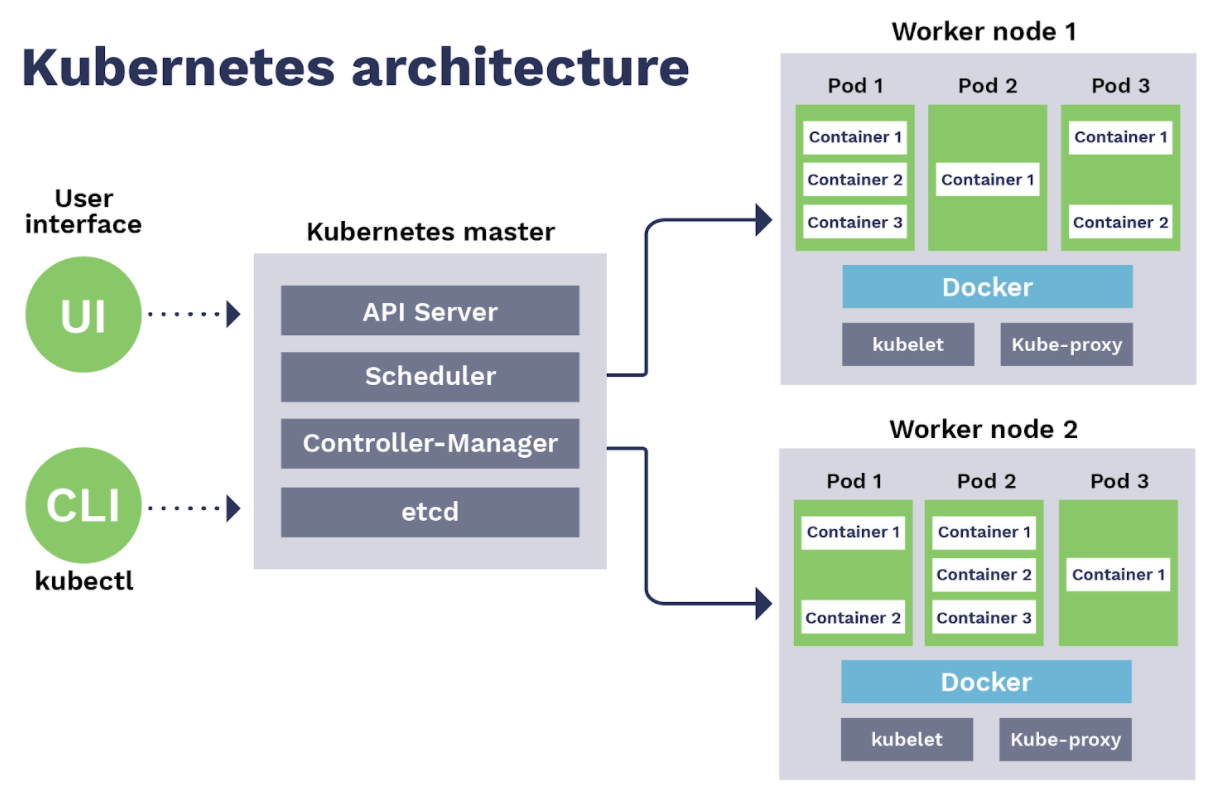
Окей, надеваем перчатки и полезли под капот: Представим, что у нас есть несколько серверов, на которых нужно развернуть наше приложение при помощи кубернетеса. Такое объединение серверов мы назовем кластером, а каждый отдельный сервачок внутри кластера назовем нодой Ноды мы логически разделим на два типа - это Мастер (Master) нода, этакий мозг нашего кластера, который будет управлять всеми остальными, и рабочие лошадки - Воркер (Worker) ноды, на них как раз будут запущены контейнеры с сервисами нашей апликухи. Еще ту часть с мозгами называют Control Plane (Control Plane), а часть где крутится приложения - Data Plane (Data Plane). Рассмотрим магистра йоду, ой, сорри, мастер ноду. Тут работает несколько процессов, нужные для запуска и управления всего кластера. Первый компонент мастер ноды - API Server. По сути это наш способ взаимодействия с кластером. Если нужно что - то сделать, то запрос идет в этот компонент. Следом идет Controller Manager. Роль этого джентльмена в наблюдении за всем кластером, проверке все ли в порядке, а если что - то не так - ему надо принимать меры. У Controller Manager есть план, которого все в кластере должны придерживаться - такой план называется “Желаемое состояние” (desired state), то есть то, как все должно работать в идеале, и задача контроллера всегда приводить текущее состояние (current state) к желаемому. Кстати, есть разные типы контроллеров, каждый из которых отвечает за узлы, реплики, токены, ну и так далее. Следующий компонент - планировщик (Scheduler). Как ты мог догадаться - он планирует. Планирует то, как расположить контейнеры на различных нодах кластера в зависимости от различных факторов, таких как загруженность ноды и доступность серверных мощностей на ней. Ну и наконец etcd (е ти си ди) - это хранилище данных в виде ключ-значение (key-value). Здесь хранится важная информация, которая отражает текущее состояние кластера: конфигурационные данные, статусы наших нод и контейнеров ну и так далее. Если что - то упадет, то эти данные помогут быстро восстановить систему. Ну вот, теперь ты понял, насколько важна мастер нода. Ну и как говорится, “Two is One and One is None” (“Два это один, один это ничто”) - так что не поленись всегда создавать резервную мастер ноду для отказоустойчивости. Переходим к обычным работягам - воркер нодам. Именно здесь сосредоточена вся мощь нашего кластера, ведь тут будут крутится наши контейнеры. У воркера три основных компонента. Первый - кублет (kubelet). Он отвечает за общение с мастером, получая инструкции что и как должно работать на этой конкретной ноде. А еще он общается со вторым компонентом - с исполняемой средой контейнера (container runtime), которая отвечает за образы контейнеров, их запуск и остановку, а также управление их ресурсами. Ну и финально, третий компонент - кьюб прокси (kube-proxy). Он выполняет сетевую роль - отвечает за коммуникацию и балансировку внутренней сети. Так, ладно, это все конечно хорошо, а где сами контейнеры то запускаются? И тут у нас появляется такая штука, которая называется под. Под (pod) - это минимальный элемент кумбера, с которым мы можем взаимодействовать. Именно в нем и запускается наш контейнер. Откровенно говоря, это некая обертка над ним. Обычно, в одном поде крутится один контейнер, но если нам по какой-то причине нужно засунуть туда больше чем один, например, когда приложению нужны доп. контейнеры для работы, то можно так сделать - это вполне легально и делается без смс и регистрации. Так вот, эти поды распределены по всем нашим воркер нодам, и на каждом воркере обычно запускается несколько различных подов. И вот этими подами кукумбер как раз и жонглирует в процессе работы программы: если на какой-то компонент увеличивается нагрузка, то мы поднимаем еще нужных pods, и стопаем их, когда они не нужны, или пересоздаем, если нода, на которой они крутились, например, решила прилечь. Ну, а если что-то случилось с самим контейнером внутри пода, то под позаботится о том, чтобы привести его в чувство. Подам конечно же нужно общаться и между собой и с внешним миром, поэтому каждому поду назначается свой собственный айпи адрес, по которому к ним можно достучаться. Однако, есть интересный нюанс - поскольку поды довольно таки эфемерны, то они могут постоянно перезапускаться в процессе работы программы и менять айпи адрес. И как продолжать общение в таких ситуациях? На помощь приходит компонент под названием сервис (Service), который выполняет сразу несколько полезных вещей. Во-первых, он логически объединяет поды в группы, которые принадлежат к одному сервису. Объединив их, он выдает этой группе постоянный айпишник, что обеспечивает их доступность. Ну а во-вторых - он обеспечивает балансировку нагрузки - поды обращаются к сервису, а он по умному распределяет запросы между своими подами. Круто ведь, да? Добро пожаловать на борт! Понимаешь, да? Ну типа кормчий, как на корабле.. типа рулит..эээ.. руководит блоком развития.. ахах…ладно. А как это все настраивается, спросишь ты? Это происходит при помощи запроса на наш API сервер, который находится на мастере. В таком запросе мы передаем файл конфигурации, обычно в формате YAML, в котором описываем в декларативном стиле все, что нам нужно. Декларативный стиль - это когда мы описываем не то, что мы хотим сделать, а то, что мы хотим получить, а умная машина сделает все за нас, в том числе, заберет нашу работу. Шутка, не заберет.
Вот тебе пример: есть у нас конфиг для компонента, который называется Deployment , это то с чем работает один из наших контроллеров (deployment-controller). По сути, это просто шаблон, по которому будут создаваться наши поды. Смотри, из важного тут мы говорим, что у нас будет запущено 3 пода (spec:replicas:), каждый из которых будет будет содержать в себе контейнер, основанный на образе nginx (энджинкс) (spec:template:spec:containers:image). Еще в этом блоке можно задать дополнительные настройки, типа переменные окружения, порты или лимиты по ресурсам. То, что мы описали, это как раз и есть желаемое состояние, к которому к8s будет стремиться привести систему. Раз мы захотели 3 пода, значит их и поднимется 3, а если один из них упадет, то контроллер менеджер увидит, что появилось несоответствие и пойдет все исправлять. Вот такие пироги! Надеемся, тебе стало понятнее что такое к8с и теперь ты тоже сможешь перебрасываться модными словечками с коллегами! Ну и напоследок вопрос - название kubernetes часто пишут как k8s, что это значит и кто это вообще придумал?












